Transforming Creative Concepts into Professional Audio with Algorithmic Composition
For decades, the ability to produce high-quality music was a privilege reserved for those with extensive theoretical knowledge and access to expensive recording studios. This barrier often left content creators, filmmakers, and storytellers struggling to find original, royalty-free background scores that perfectly matched their vision. The frustration of scrolling through stock audio libraries only to find generic tracks is a common pain point for digital creatives. Fortunately, the landscape of digital audio production has shifted dramatically with the emergence of the AI Music Generator, a tool designed to bridge the gap between abstract ideas and fully realized musical compositions.
This technology does not merely assemble pre-recorded loops; it synthesizes new audio based on textual input, effectively acting as a collaborative studio partner. By leveraging advanced neural networks, these platforms can interpret emotional nuance, genre constraints, and lyrical content to produce unique songs. The democratization of music production allows users to focus on the narrative and emotional impact of their projects rather than the technical complexities of mixing and mastering. As we explore the capabilities of this specific platform, we will analyze how it functions, its practical applications, and the realistic expectations users should maintain regarding Text to Music AI.
Understanding the Core Mechanics of Text to Audio Synthesis
The fundamental appeal of this platform lies in its ability to convert natural language into complex auditory signals. Unlike traditional synthesizers that require manual programming of oscillators and envelopes, this system utilizes large language models trained on vast datasets of musical structures. When a user inputs a prompt, the AI analyzes the semantic meaning—identifying keywords related to mood, instrumentation, and tempo—and maps them to corresponding acoustic patterns.
From Simple Text Prompts to Fully Orchestrated Melodies
The engine operates by predicting the sequence of audio waveforms that logically follow a given text input. For instance, a prompt describing a “melancholic piano ballad with soft rain sounds” triggers the model to select minor chord progressions, slow tempos, and specific textural layers. The system is designed to understand both technical musical terms and abstract emotional descriptors. This dual understanding allows for a high degree of flexibility, enabling users to experiment with genre-blending, such as combining “futuristic synth-wave” with “classical violin solos,” a task that would be challenging for a human composer to execute instantly.
Distinguishing Between Lyric Generation and Instrumental Arrangement
A critical distinction in this technology is its handling of vocals versus instrumentals. The platform creates a cohesive track where the melody is generated simultaneously with the backing track, ensuring that the rhythm and pitch of the vocals align with the harmony. This differs from older text-to-speech overlays, where a robotic voice was simply placed on top of a beat. Here, the AI models vocal nuances, including breath, vibrato, and dynamic shifts, to mimic human performance styles relevant to the chosen genre, whether it is a gritty rock anthem or a polished pop track.
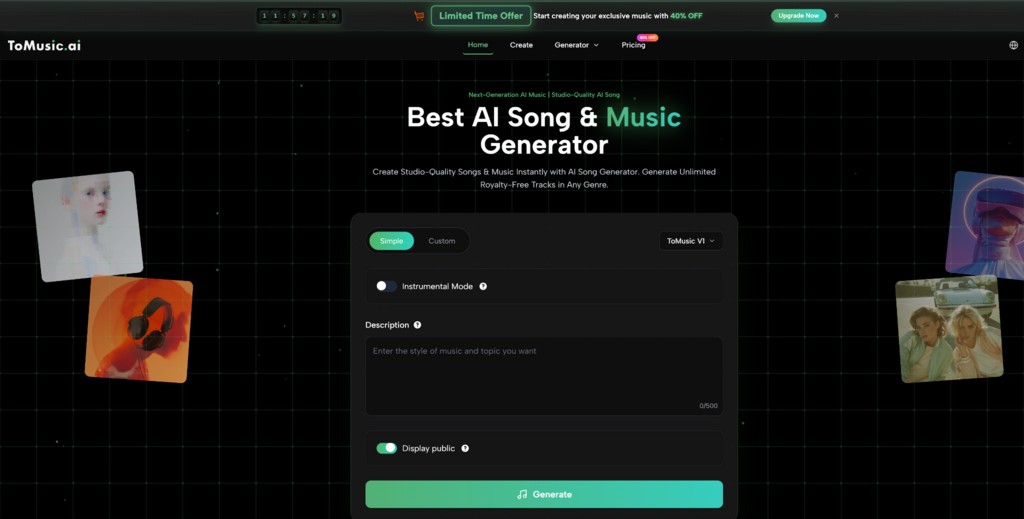
Navigating the Creation Process on the Platform
The user interface is streamlined to minimize technical friction, guiding the creator through a logical flow of operations. The process is designed to be iterative, allowing users to refine their results through adjustments in their input data. Based on the official workflow, the generation process can be broken down into three distinct phases that transition from concept to final audio file.
Step One Inputting Lyrics and Descriptive Prompts
The initial phase involves defining the core content of the song. Users are presented with a text box where they can either type in their own custom lyrics or provide a topic for the AI to generate lyrics automatically. This stage is crucial as it sets the thematic foundation. Simultaneously, the user must provide a style description. This is where the prompt engineering comes into play; detailed descriptions yielding better results. For example, specifying “upbeat pop, female vocals, summer vibes” provides the AI with clear constraints for the generation process.
Step Two Configuring Musical Parameters and Model Selection
Once the text is in place, the second step involves technical configuration. The platform allows users to toggle between different model versions, such as V1 through V4, each offering different levels of fidelity and stylistic adherence. Users can select the desired duration of the track and specific instrumental modes if vocals are not required. This stage also includes the “Custom Mode” settings, where users can fine-tune the output by selecting distinct musical tags (e.g., Jazz, Metal, Lo-Fi) and enabling or disabling automatic generation features to have more manual control over the structure.
Step Three Generating and Refining the Final Audio Output
The final step is the execution command. Upon clicking the generate button, the request is sent to the processing queue. Within a short period, typically under a minute for standard lengths, the system returns two distinct variations of the song based on the provided inputs. This dual-output mechanism is essential as it gives the user options regarding melody and phrasing. From here, the user can preview the tracks, download the preferred version in audio or video format, or choose to extend the track if the composition needs to be longer than the initial generation.

Evaluating the Technical Capabilities and Feature Sets
Beyond the basic generation workflow, the platform integrates several advanced features that cater to more professional use cases. These features suggest a move towards a comprehensive production suite rather than just a novelty toy. The ability to manipulate the generated audio post-creation is a significant factor in its utility for content creators.
Analyzing the Differences Between Model Versions V1 to V4
The progression from Model V1 to V4 represents a leap in audio fidelity and compositional complexity. In my observation of the technical specifications, V1 serves as a base model suitable for quick ideation and shorter clips. In contrast, V4 is engineered for “Studio Quality” output. This advanced model demonstrates a superior understanding of song structure, capable of generating verse-chorus-bridge patterns that feel more organic. Furthermore, V4 supports longer generation times, up to several minutes in a single pass, which reduces the disjointed feeling that can sometimes occur when stitching shorter clips together.
Assessing Vocal Fidelity and Instrumental Separation Features
One of the more sophisticated tools available is the “Stem Separation” feature. In traditional music production, separating vocals from a mixed track is a complex process often fraught with artifacts. This platform builds this capability directly into the workflow, allowing users to download the vocal track and the instrumental backing track separately. This is particularly valuable for video editors who may need to duck the music under dialogue or for remixers looking to isolate specific elements. Additionally, the vocal generation has improved to include more realistic human characteristics, reducing the metallic “autotune” artifacting common in early AI audio models.
Comparing Subscription Tiers and Commercial Licensing Rights
For users considering this tool for professional projects, understanding the distinction between free exploration and paid utility is vital. The platform operates on a credit-based system, where higher tiers unlock not just more quantity, but significantly higher quality and legal rights. The availability of a Commercial License is the tipping point for YouTubers, podcasters, and advertisers who need to monetize their content without fear of copyright strikes.
Balancing Cost Versus Advanced Production Features
The following table outlines the key differences observed between the entry-level and professional access tiers, highlighting where the value proposition lies for different types of users.
| Feature Category | Starter / Free Access | Professional / Unlimited Plan |
| Model Access | Limited to V1 Model | Full Access (V1, V2, V3, V4) |
| Track Duration | Short clips (approx. 4 mins) | Extended capability (up to 8 mins) |
| Download Format | Standard MP3 | High-fidelity WAV & MP3 |
| Commercial Rights | Personal use only | Full Commercial License |
| Concurrent Jobs | Single generation queue | Multiple concurrent generations |
| Advanced Tools | Basic generation only | Stem Separation, Extensions, Cover Songs |
Recognizing Limitations in Algorithmic Music Generation
While the technology is impressive, it is important to maintain a realistic perspective on its current limitations. In my analysis of the output, while the audio quality is high, the “creativity” is strictly derivative of the training data. This means that while the AI can mimic a style perfectly, it may struggle to innovate a completely new genre. Furthermore, specific prompts can sometimes yield unpredictable results; a request for a specific, complex melody line might result in a generic approximation. Users should view this as a powerful tool for background scoring, ideation, and rapid prototyping, rather than a total replacement for human virtuosity in emotionally complex compositions. The generated lyrics, if not custom-written by the user, can occasionally lack depth or logical flow, necessitating human intervention for the best lyrical results.